
Cicero: A Declarative Grammar for Responsive Visualization
Hyeok Kim, Ryan Rossi, Fan Du, Eunyee Koh, Shunan Guo, Jessica Hullman, Jane Hoffswell
ACM Human Factors in Computing Systems (CHI) 2022
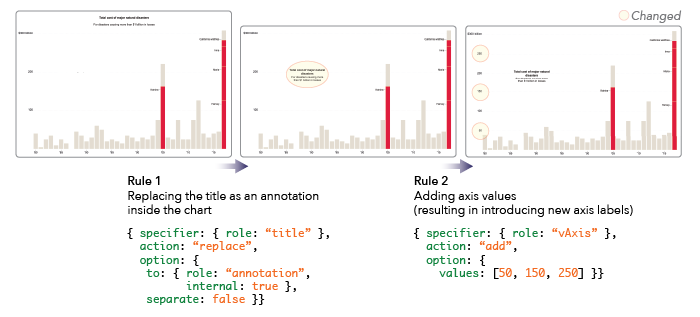
Responsive visualization techniques to utilize increases screen space, expressed in Cicero. Rule 1 internalizes the chart title. Rule 2 adds more axis values, resulting in new axis labels.
Abstract
Designing responsive visualizations can be cast as applying transformations to a source view to render it suitable for a different screen size. However, designing responsive visualizations is often tedious as authors must manually apply and reason about candidate transformations. We present Cicero, a declarative grammar for concisely specifying responsive visualization transformations which paves the way for more intelligent responsive visualization authoring tools. Cicero’s flexible specifier syntax allows authors to select visualization elements to transform, independent of the source view’s structure. Cicero encodes a concise set of actions to encode a diverse set of transformations in both desktop-first and mobile-first design processes. Authors can ultimately reuse design-agnostic transformations across different visualizations. To demonstrate the utility of Cicero, we develop a compiler to an extended version of Vega-Lite, and provide principles for our com- piler. We further discuss the incorporation of Cicero into responsive visualization authoring tools, such as a design recommender.