
A Decision Theoretic Framework for Measuring AI Reliance
Ziyang Guo, Yifan Wu, Jason Hartline, Jessica Hullman
ACM Conference on Fairness, Accountability, and Transparency (ACM FAccT ’24)
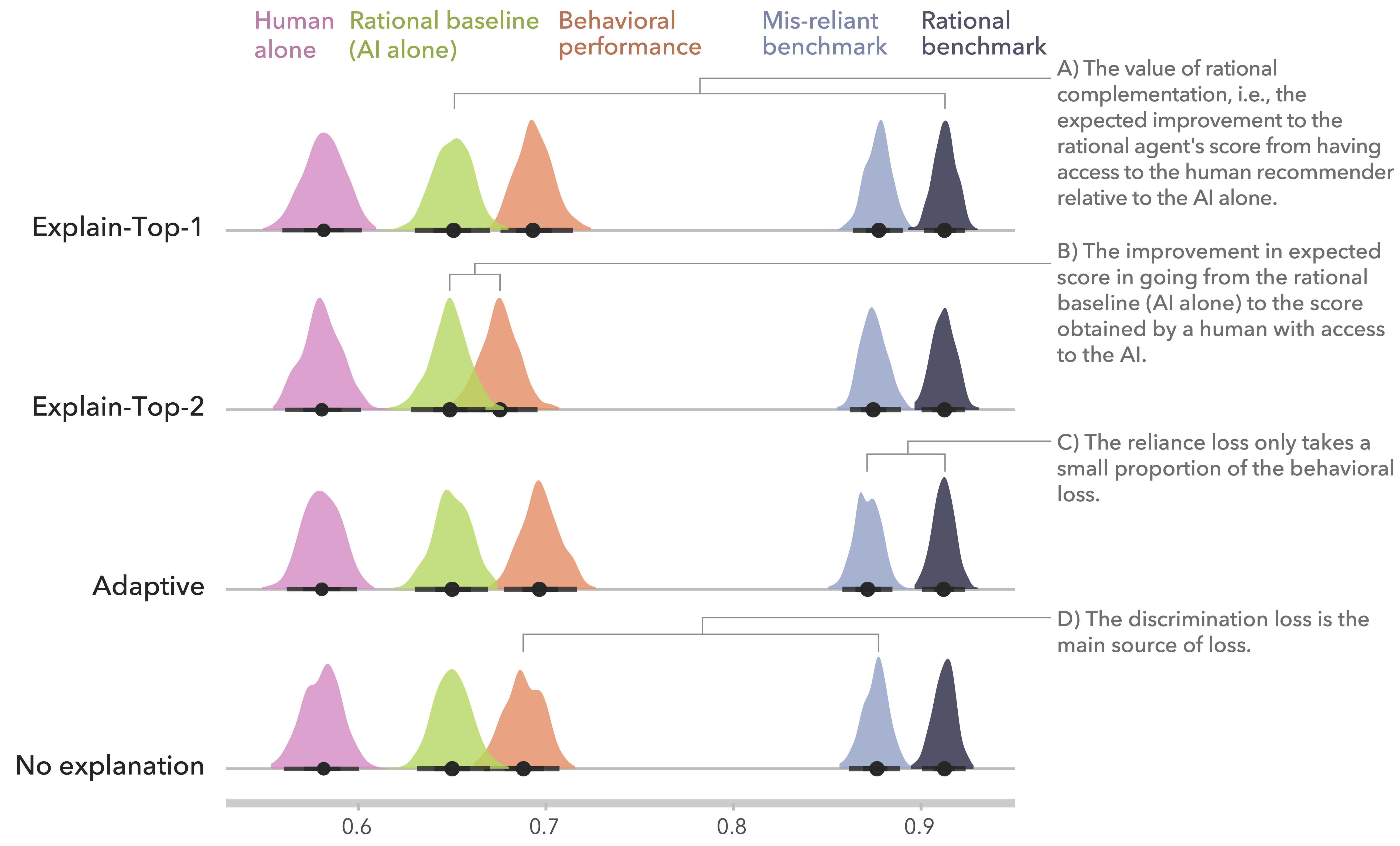
Expected payoffs of benchmarks, baselines, and observed performance in Bansal et al. in which the performance of human-AI teams (behavioral decision score, orange) overperforms human alone (human alone score, pink) or AI alone (rational baseline, green). The behavioral loss sourced from over-/under-reliance of human-AI teams (determined by the distance between mis-reliant benchmark and rational benchmark) only takes a small proportion compared with other sources.
Abstract
Humans frequently make decisions with the aid of artificially intelligent (AI) systems. A common pattern is for the AI to recommend an action to the human who retains control over the final decision. Researchers have identified ensuring that a human has appropriate reliance on an AI as a critical component of achieving complementary performance. We argue that the current definition of appropriate reliance used in such research lacks formal statistical grounding and can lead to contradictions. We propose a formal definition of reliance, based on statistical decision theory, which separates the concepts of reliance as the probability the decision-maker follows the AI’s recommendation from challenges a human may face in differentiating the signals and forming accurate beliefs about the situation. Our definition gives rise to a framework that can be used to guide the design and interpretation of studies on human-AI complementarity and reliance. Using recent AI-advised decision making studies from literature, we demonstrate how our framework can be used to separate the loss due to mis-reliance from the loss due to not accurately differentiating the signals. We evaluate these losses by comparing to a baseline and a benchmark for complementary performance defined by the expected payoff achieved by a rational decision-maker facing the same decision task as the behavioral decision-makers.